Adaptive ETA for Google Maps: Hierarchical Tile Indexing for Faster Traffic Updates
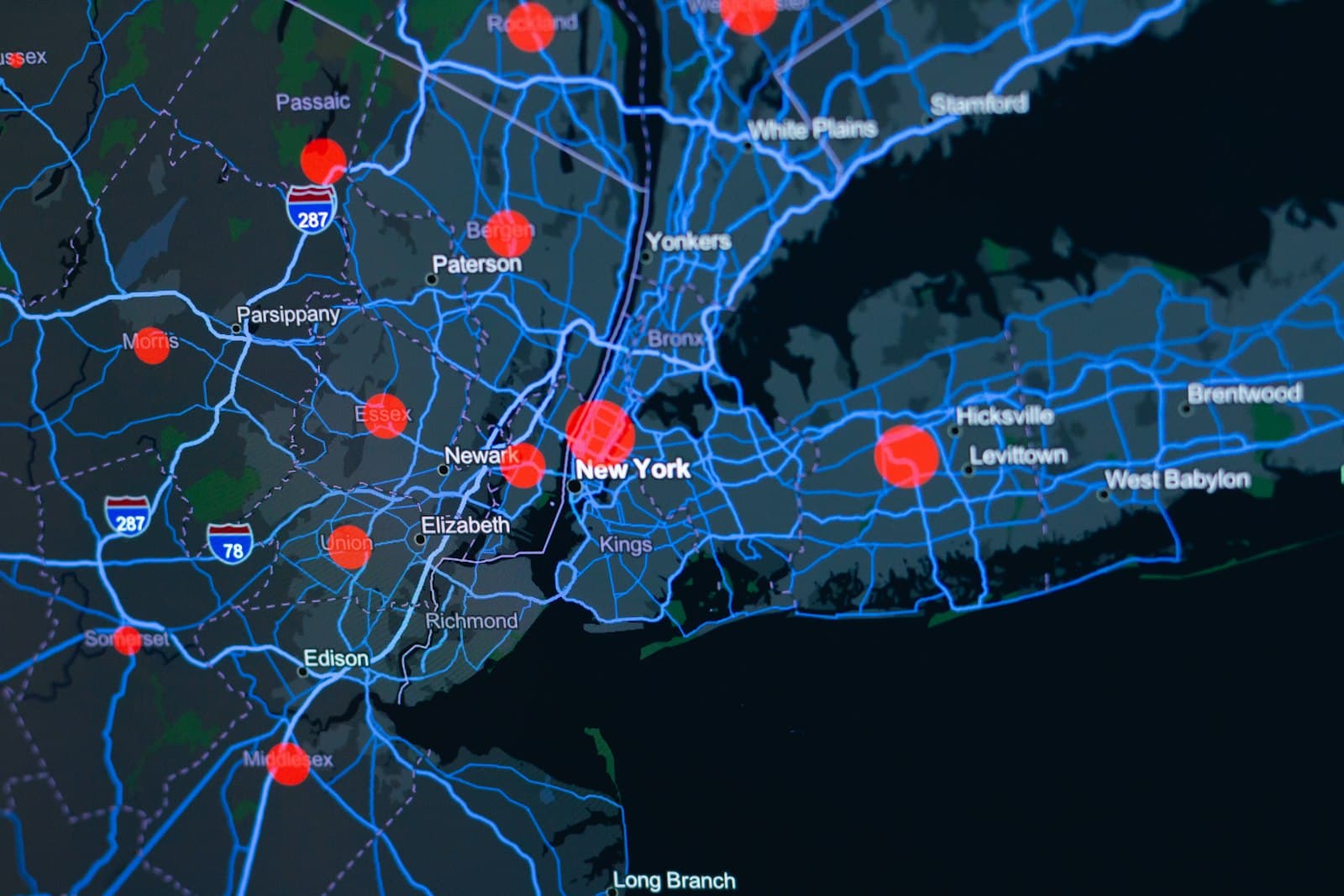
Google maps breaks map into small tiles. Now for each zoom level we store different tiles. The tiles are precomputed at different levels and stored in a CDN for faster delivery.
For better understanding, level 0 means the whole map at 256*256 pixel. At level 1 the map is divided into 4 tiles with total combined resolution of 1024*1024 pixel. Now for level 2 its 16 tiles and so on. You can easily create a genric expression for the above.

If there is a origin and destination that user needs to traverse. Below example shows the route from tile a to tile f.

Now imagine there is a huge traffic in tile c. We need to go through the whole user database scanning through each path to change the ETA for reaching at the destination. If there are N user and M average routing path length, its going to be N*M.
Is there a faster way of doing that?
What if we store the parent tile instead of each smaller tiles?

The advantage of the above representation : Just check whether the effected tile(for us it was tile c) is present in the last tile or not as it is the super parent tile.
Now our time complexity becomes N, that is number of users.
But Give this a thought:
If all the information are present in the last tile what is the requirement of the previous tiles.
Do you think the above approach is not always 100% spot on. Certain times its going to give you a false positive?
Actually the second question is the answer to the first question. It decreases the accuracy increasing the chances of false positives.
One small example: There is residential community in Narsinghi, Hyderabad and an another is Hitech city.
The first is my source and second is my destination.
How the above works
Narsinghi ---> Hyderabad -----> Telangana. Did you see the hierarchical change?
Instead of each detailed tiles we zoomed out one level at a time.
There is financial district that is nothing to do with the route that connects narsinghi and hitech city. Lets suppose there is a huge traffic there.
This would show all the paths that has hyderabad will be marked as traffic effected. But in reality that's not the case.
This is a false positive. The accuracy decreases but speed increases.
At a scale of Google Maps these are some of the trade offs worth going forward with.
Do we have a better solution? Yes we can do the above operation in multi stage process. First filter out with the last tile. This leaves us with all routes that are actually affected plus some that are not(false positives).
Our search size has decreased to a huge extent. Now we can search on a more granular details to get a better accuracy.
The principle is "Use cheap approximations to reduce search space first"