Spec-Driven Development with AI: Lessons and Pitfalls
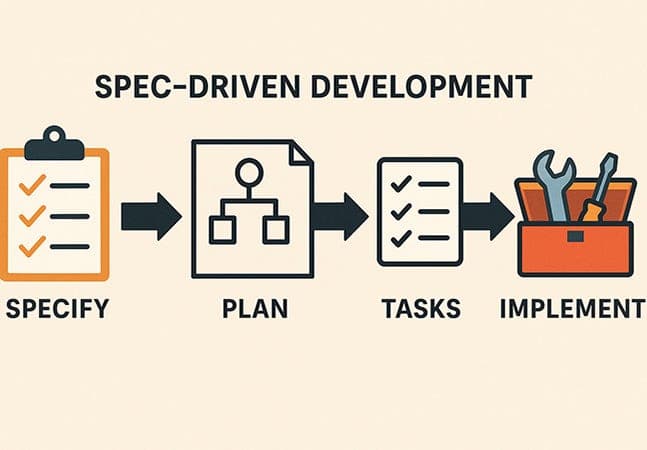
Spec-driven development (SDD) is currently one of the most talked-about approaches in AI-assisted software engineering. After extensively using it for my development purpose, The below is some stories and learning on those experimentations.
Though the SDD framework has a lot of advantages, especially adding the skills but still these frameworks are yet nowhere near perfection. It works like magic when a skill is added and used on certain task. So even if you don't have any idea of a particular process or tech stack, create a skill and use it.
Sync spec ---> code : Firstly if we are saving the specs along with our code then its a tough thing to maintain sync between the code and specs. Its better that we don't save those specs and instead treat it as a development assistant.
So many md files : Most of the SDD frameworks produce tens of md files, that would generate may be a lot of code. Its tiresome to review the code as well the specs. And personally I would prefer to review the code files than the md files.
Token Cost: With the recent increase in model pricing producing multiple md files can be a costly affair. Generating so many token might not be worth it.
Less focus on tests or overengineered tests: They generate the "How to implement" thing but then there is no focus on tests. Now as those huge number of lines of code are next to impossible to be reviewed properly by a human, Its very important that we have a way of testing our changes.
There is another instance when it created a lot of test for a simple feature and half of them failed. This a point that LLM does stupid things, mostly overengineered solutions.
Time, I thought it decreases but is it the case? : Whenever I start to implement a feature, the rigid workflow makes it a bit more time consuming. If you are discipline enough, then its fine else there is always a tendency to write a adhoc prompt outside the workflow. Something I observed is people start their development with a SDD framework but later move to the same old vibe coding practice.
Brownfield projects: SDD tools lack migration strategies for existing, complex codebases. Research could explore ways to “bootstrap” specs from legacy code or link specs to existing requirements repositories.
Bug fixes Vs Feature Development: Personally I using feature development with SDD feels nice and easy but when there is a small bug, in that case using SDD just kills a lot of time. What I prefer is just go to the codebase and make the changes.
Hallucinations on large context: When the context or the Instruction.md file increases in size, in spite of certain details clearly mentioned it misses out. You might have written that follow certain process, it might misses out on that process.
Even after clearly mentioning the specs or skills or even some guardrails spec, there is a certain amount of chances where there might be llm context poisoning and that particular information , might be missed out.
How can you compare two SDD framework. Is there an evaluation framework? Openspec might be good in implenting something while for another particular task it might be spec kit or Kiro.
SDD is still in its nascent stage, still evolving. For certain use cases, it worked really good but for certain it failed. All the different SDD frameworks have its own pros and cons but there is no way we can define then objectively. A single tool is not the best at all the use cases but we don't have a proper scientific way of defining it. There is a constant need of human in the loop who can review the specs generated whether the code generated are inline with the specs or not.
Use spec-driven AI to amplify craft, not to outsource judgment.
References:
- Martin Fowler on SDD: https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html